Fast overlap joins in SQL, Python and R
by Avinash Mallya
Premise
I stumbled upon an interesting Stackoverflow question that was linked via an issue on Polars github repo. The OP asked for a pure Polars solution. At the time of answering the question Polars did not have support for non-equi joins, and any solution using it would be pretty cumbersome.
I’m more of a right-tool-for-the-job person, so I tried to find a better solution.
Problem Statement
Suppose we have a dataset that captures the arrival and departure times of trucks at a station, along with the truck’s ID.
import polars as pl # if you don't have polars, run
# pip install 'polars[all]'
data = pl.from_repr("""
┌─────────────────────┬─────────────────────┬─────┐
│ arrival_time ┆ departure_time ┆ ID │
│ --- ┆ --- ┆ --- │
│ datetime[μs] ┆ datetime[μs] ┆ str │
╞═════════════════════╪═════════════════════╪═════╡
│ 2023-01-01 06:23:47 ┆ 2023-01-01 06:25:08 ┆ A1 │
│ 2023-01-01 06:26:42 ┆ 2023-01-01 06:28:02 ┆ A1 │
│ 2023-01-01 06:30:20 ┆ 2023-01-01 06:35:01 ┆ A5 │
│ 2023-01-01 06:32:06 ┆ 2023-01-01 06:33:48 ┆ A6 │
│ 2023-01-01 06:33:09 ┆ 2023-01-01 06:36:01 ┆ B3 │
│ 2023-01-01 06:34:08 ┆ 2023-01-01 06:39:49 ┆ C3 │
│ 2023-01-01 06:36:40 ┆ 2023-01-01 06:38:34 ┆ A6 │
│ 2023-01-01 06:37:43 ┆ 2023-01-01 06:40:48 ┆ A5 │
│ 2023-01-01 06:39:48 ┆ 2023-01-01 06:46:10 ┆ A6 │
└─────────────────────┴─────────────────────┴─────┘
""")
We want to identify the number of trucks docked at any given time within a threshold of 1 minute prior to the arrival time of a truck, and 1 minute after the departure of a truck. Equivalently, this means that we need to calculate the number of trucks within a specific window for each row of the data.
Finding a solution to the problem
Evaluate for a specific row
Before we find a general solution to this problem, let’s consider a specific row to understand the problem better:
"""
┌─────────────────────┬─────────────────────┬─────┐
│ arrival_time ┆ departure_time ┆ ID │
│ --- ┆ --- ┆ --- │
│ datetime[μs] ┆ datetime[μs] ┆ str │
╞═════════════════════╪═════════════════════╪═════╡
│ 2023-01-01 06:32:06 ┆ 2023-01-01 06:33:48 ┆ A6 │
└─────────────────────┴─────────────────────┴─────┘
"""
For this row, we need to find the number of trucks that are there between 2023-01-01 06:31:06 (1 minute prior to the arrival_time and 2023-01-01 06:34:48 (1 minute post the departure_time). Manually going through the original dataset, we see that B3, C3, A6 and A5 are the truck IDs that qualify - they all are at the station in a duration that is between 2023-01-01 06:31:06 and 2023-01-01 06:34:48.
Visually deriving an algorithm
There are many cases that will qualify a truck to be present in the overlap window defined by a particular row. Specifically for the example above, we have (this visualization is generalizable, because for each row we can calculate without much difficulty the overlap window relative to the arrival and departure times):
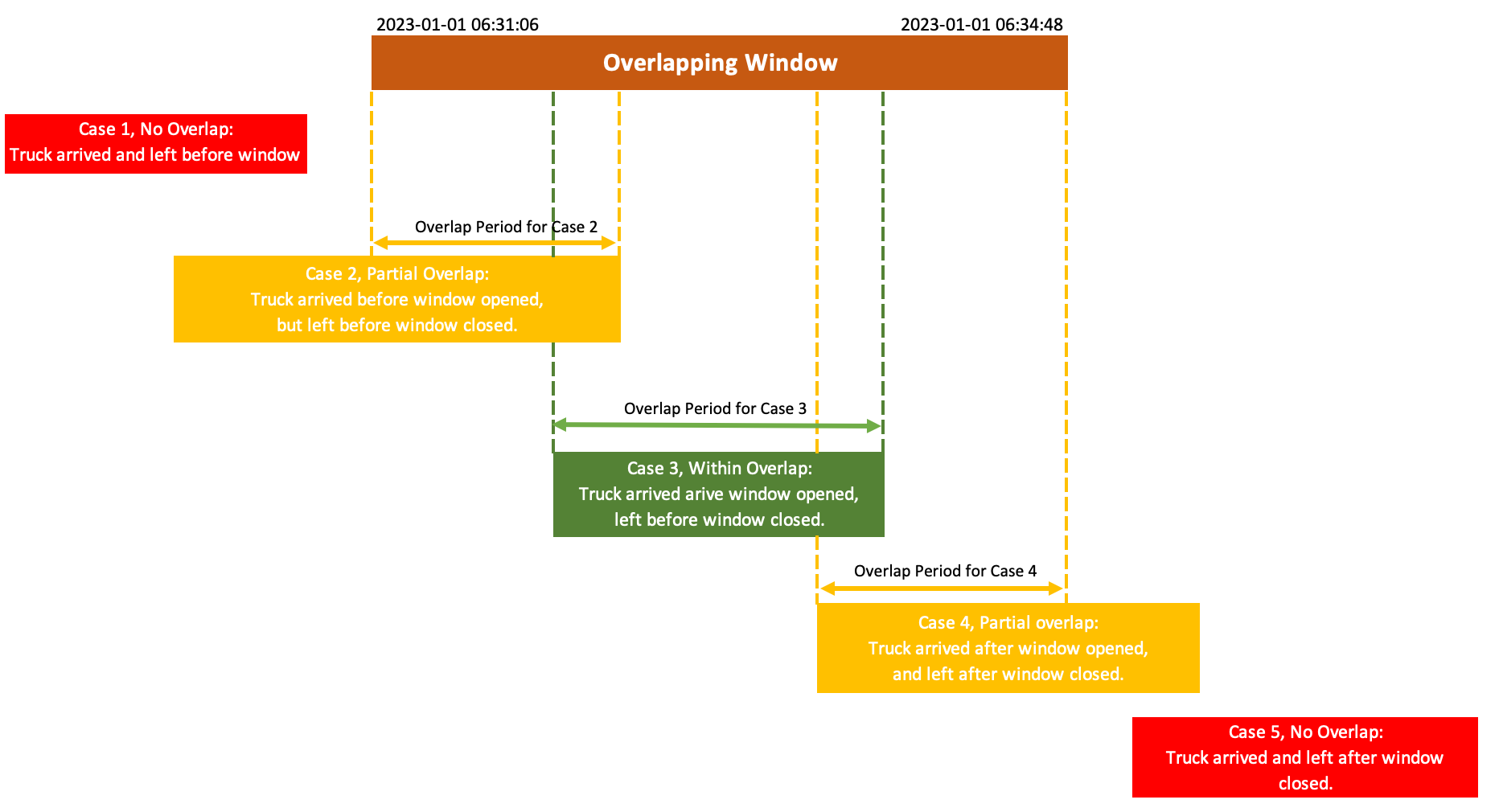
Take some time to absorb these cases - it’s important for the part where we write the code for the solution. Note that we need to actually tell our algorithm to filter only for Cases 2, 3 and 4, since Cases 1 and 5 will not satisfy our requirements.
Writing an SQL query based on the algorithm
In theory, we can use any language that has the capability to define rules that meet our algorithmic requirements outlined in the above section to find the solution. Why choose SQL? It’s often able to convey elegantly the logic that was used to execute the algorithm; and while it does come with excessive verbosity at times, it doesn’t quite in this case.
Note here that we run SQL in Python with almost no setup or boilerplate code - so this is a Python based solution as well (although not quite Pythonic!).
Introducing the DuckDB package
Once again, in theory, any SQL package or language can be used. Far too few however meet the ease-of-use that DuckDB provides:
- no expensive set-up time (meaning no need for setting up databases, even temporary ones),
- no dependencies (other than DuckDB itself, just
pip install duckdb), - some very friendly SQL extensions, and
- ability to work directly on Polars and Pandas DataFrames without conversions
all with mind-blowing speed that stands shoulder-to-shoulder with Polars. We’ll also use a few advanced SQL concepts noted below.
Self-joins
This should be a familiar, albeit not often used concept - a join of a table with itself is a self join. There are few cases where such an operation would make sense, and this happens to be one of them.
A bullet train recap of non-equi joins
A key concept that we’ll use is the idea of joining on a range of values rather than a specific value. That is, instead of the usual LEFT JOIN ON A.column = B.column, we can do LEFT JOIN ON A.column <= B.column for one row in table A to match to multiple rows in B. DuckDB has a blog post that outlines this join in detail, including fast implementation.
The concept of LIST columns
DuckDB has first class support for LIST columns - that is, each row in a LIST column can have a varying length (much like a Python list), but must have the exact same datatype (like R’s vector). Using list columns allow us to eschew the use of an additional GROUP BY operation on top of a WHERE filter or SELECT DISTINCT operation, since we can directly perform those on the LIST column itself.
Date algebra
Dates can be rather difficult to handle well in most tools and languages, with several packages purpose built to make handling them easier - lubridate from the tidyverse is a stellar example. Thankfully, DuckDB provides a similar swiss-knife set of tools to deal with it, including specifying INTERVALs (a special data type that represent a period of time independent of specific time values) to modify TIMESTAMP values using addition or subtraction.
Tell me the query, PLEASE!
Okay - had a lot of background. Let’s have at it! The query by itself in SQL is (see immediately below for runnable code in Python):
SELECT
A.arrival_time
,A.departure_time
,A.window_open
,A.window_close
,LIST_DISTINCT(LIST(B.ID)) AS docked_trucks
,LIST_UNIQUE(LIST(B.ID)) AS docked_truck_count
FROM (
SELECT *
,arrival_time - (INTERVAL 1 MINUTE) AS window_open
,departure_time + (INTERVAL 1 MINUTE) AS window_close
FROM data) A
LEFT JOIN (
SELECT *
,DATEDIFF('seconds', arrival_time, departure_time) AS duration
FROM data) B
ON ((B.arrival_time <= A.window_open AND
(B.arrival_time + TO_SECONDS(B.duration)) >= A.window_open) OR
(B.arrival_time >= A.window_open AND
B.departure_time <= A.window_close) OR
(B.arrival_time >= A.window_open AND
(B.departure_time - TO_SECONDS(B.duration)) <= A.window_close))
GROUP BY 1, 2, 3, 4
A small, succinct query such as this will need a bit of explanation to take it all in. Here’s one below, reproducible in Python (make sure to install duckdb first!). Expand it to view.
SQL with explanation.
import duckdb as db
db.query("""
SELECT
A.arrival_time
,A.departure_time
,A.window_open
,A.window_close
-- LIST aggregates the values into a LIST column
-- and LIST_DISTINCT finds the unique values in it
,LIST_DISTINCT(LIST(B.ID)) AS docked_trucks
-- finally, LIST_UNIQUE calculates the unique number of values in it
,LIST_UNIQUE(LIST(B.ID)) AS docked_truck_count
FROM (
SELECT
*
,arrival_time - (INTERVAL 1 MINUTE) AS window_open
,departure_time + (INTERVAL 1 MINUTE) AS window_close
FROM data -- remember we defined data as the Polars DataFrame with our truck station data
) A
LEFT JOIN (
SELECT
*
-- This is the time, in seconds between the arrival and departure of
-- each truck PER ROW in the original data-frame
,DATEDIFF('seconds', arrival_time, departure_time) AS duration
FROM data -- this is where we perform a self-join
) B
ON (
-- Case 2 in the diagram;
(B.arrival_time <= A.window_open AND
-- Adding the duration here makes sure that the second interval
-- is at least ENDING AFTER the start of the overlap window
(B.arrival_time + TO_SECONDS(B.duration)) >= A.window_open) OR
-- Case 3 in the diagram - the simplest of all five cases
(B.arrival_time >= A.window_open AND
B.departure_time <= A.window_close) OR
-- Case 4 in the digram;
(B.arrival_time >= A.window_open AND
-- Subtracting the duration here makes sure that the second interval
-- STARTS BEFORE the end of the overlap window.
(B.departure_time - TO_SECONDS(B.duration)) <= A.window_close)
)
GROUP BY 1, 2, 3, 4
""")
The output of this query is:
"""
┌─────────────────────┬─────────────────────┬─────────────────────┬───┬──────────────────┬────────────────────┐
│ arrival_time │ departure_time │ window_open │ … │ docked_trucks │ docked_truck_count │
│ timestamp │ timestamp │ timestamp │ │ varchar[] │ uint64 │
├─────────────────────┼─────────────────────┼─────────────────────┼───┼──────────────────┼────────────────────┤
│ 2023-01-01 06:23:47 │ 2023-01-01 06:25:08 │ 2023-01-01 06:22:47 │ … │ [A1] │ 1 │
│ 2023-01-01 06:26:42 │ 2023-01-01 06:28:02 │ 2023-01-01 06:25:42 │ … │ [A1] │ 1 │
│ 2023-01-01 06:30:20 │ 2023-01-01 06:35:01 │ 2023-01-01 06:29:20 │ … │ [B3, C3, A6, A5] │ 4 │
│ 2023-01-01 06:32:06 │ 2023-01-01 06:33:48 │ 2023-01-01 06:31:06 │ … │ [B3, C3, A6, A5] │ 4 │
│ 2023-01-01 06:33:09 │ 2023-01-01 06:36:01 │ 2023-01-01 06:32:09 │ … │ [B3, C3, A6, A5] │ 4 │
│ 2023-01-01 06:34:08 │ 2023-01-01 06:39:49 │ 2023-01-01 06:33:08 │ … │ [B3, C3, A6, A5] │ 4 │
│ 2023-01-01 06:36:40 │ 2023-01-01 06:38:34 │ 2023-01-01 06:35:40 │ … │ [A5, A6, C3, B3] │ 4 │
│ 2023-01-01 06:37:43 │ 2023-01-01 06:40:48 │ 2023-01-01 06:36:43 │ … │ [A5, A6, C3] │ 3 │
│ 2023-01-01 06:39:48 │ 2023-01-01 06:46:10 │ 2023-01-01 06:38:48 │ … │ [A6, A5, C3] │ 3 │
├─────────────────────┴─────────────────────┴─────────────────────┴───┴──────────────────┴────────────────────┤
│ 9 rows 6 columns (5 shown) │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
"""
We clearly see the strengths of DuckDB in how succintly we were able to express this operation. We also find how DuckDB is able to seamlessly integrate with an existing Pandas or Polars pipeline with zero-conversion costs. In fact, we can convert this back to a Polars or Pandas dataframe by appending the ending bracket with db.query(...).pl() and db.query(...).pd() respectively.
Can we make the SQL simpler?
Now that we’ve understood the logic that goes into the query, let’s try to optimize the algorithm. We have the three conditions:
-- Case 2 in the diagram
(B.arrival_time <= A.window_open AND
(B.arrival_time + TO_SECONDS(B.duration)) >= A.window_open) OR
-- Case 3 in the diagram
(B.arrival_time >= A.window_open AND
B.departure_time <= A.window_close) OR
-- Case 4 in the diagram
(B.arrival_time >= A.window_open AND
(B.departure_time - TO_SECONDS(B.duration)) <= A.window_close)
What is common between these three conditions? It takes a while to see it; but it becomes clear that all these cases require the start of the overlap to be before the window ends, and the end of the overlap to be after the window starts. This can be simplified to just:
B.arrival_time <= A.window_close AND
B.departure_time >= A.window_open
making our query much simpler!
Simplified SQL: Part 1
We’ve removed the need for the duration calculation algother now. Therefore, we can write:
SELECT
A.arrival_time
,A.departure_time
,A.window_open
,A.window_close
,LIST_DISTINCT(LIST(B.ID)) AS docked_trucks
,LIST_UNIQUE(LIST(B.ID)) AS docked_truck_count
FROM (
SELECT *
,arrival_time - (INTERVAL 1 MINUTE) AS window_open
,departure_time + (INTERVAL 1 MINUTE) AS window_close
FROM data) A
LEFT JOIN data B
ON (
B.arrival_time <= A.window_close AND
B.departure_time >= A.window_open
)
GROUP BY 1, 2, 3, 4
Can we simplify this even further?
Simplification: Part 2
I think the SQL query in the above section is very easy to ready already. However, it is a little clunky overall, and there is a way that we can leverage DuckDB’s extensive optimizations to simplify our legibility by rewriting the query as a cross join:
SELECT
A.arrival_time
,A.departure_time
,A.arrival_time - (INTERVAL 1 MINUTE) AS window_open
,A.departure_time + (INTERVAL 1 MINUTE) AS window_close
,LIST_DISTINCT(LIST(B.ID)) AS docked_trucks
,LIST_UNIQUE(LIST(B.ID)) AS docked_truck_count
FROM data A, data B
WHERE B.arrival_time <= window_close
AND B.departure_time >= window_open
GROUP BY 1, 2, 3, 4
Why does this work? Before optimization on DuckDB, this is what the query plan looks like:
DuckDB query plan before optimization
"""
┌───────────────────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ 0 │
│ 1 │
│ 2 │
│ 3 │
│ docked_trucks │
│ docked_truck_count │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ AGGREGATE │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ arrival_time │
│ departure_time │
│ window_open │
│ window_close │
│ list(ID) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ FILTER │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ (arrival_time <= │
│(departure_time + to_m... │
│ AS BIGINT)))) │
│ (departure_time >= │
│(arrival_time - to_min... │
│ AS BIGINT)))) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ CROSS_PRODUCT ├──────────────┐
└─────────────┬─────────────┘ │
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ ARROW_SCAN ││ ARROW_SCAN │
└───────────────────────────┘└───────────────────────────┘
"""
After optimization, the CROSS_PRODUCT is automatically optimized to an interval join!
DuckDB query after before optimization
"""
┌───────────────────────────┐
│ PROJECTION │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ 0 │
│ 1 │
│ 2 │
│ 3 │
│ docked_trucks │
│ docked_truck_count │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ AGGREGATE │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ arrival_time │
│ departure_time │
│ window_open │
│ window_close │
│ list(ID) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ COMPARISON_JOIN │
│ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ INNER │
│ ((departure_time + '00:01 │
│ :00'::INTERVAL) >= ├──────────────┐
│ arrival_time) │ │
│((arrival_time - '00:01:00'│ │
│ ::INTERVAL) <= │ │
│ departure_time) │ │
└─────────────┬─────────────┘ │
┌─────────────┴─────────────┐┌─────────────┴─────────────┐
│ ARROW_SCAN ││ ARROW_SCAN │
└───────────────────────────┘└───────────────────────────┘
"""
So in effect, we’re actually exploiting a feature of DuckDB to allow us to write our queries in a suboptimal manner for greater readability, and allowing the optmizer to do a good chunk of our work for us. I wouldn’t recommend using this generally, because not all SQL engine optmizers will be able to find an efficient route to these calculations for large datasets.
How to get query plans?
I’m glad you asked. Here’s the DuckDB page explaining EXPLAIN (heh). Here’s the code I used:
import duckdb as db
db.sql("SET EXPLAIN_OUTPUT='all';")
print(db.query("""
EXPLAIN
SELECT
A.arrival_time
,A.departure_time
,A.arrival_time - (INTERVAL 1 MINUTE) AS window_open
,A.departure_time + (INTERVAL 1 MINUTE) AS window_close
,LIST_DISTINCT(LIST(B.ID)) AS docked_trucks
,LIST_UNIQUE(LIST(B.ID)) AS docked_truck_count
FROM data A, data B
WHERE B.arrival_time <= window_close
AND B.departure_time >= window_open
GROUP BY 1, 2, 3, 4
""").pl()[1, 1])
What are the alternatives?
The data.table way
data.table is a package that has historically been ahead of its time - in both speed and features that it has had. Developement has taken a hit recently, but will likely pick back up. It’s my favourite package on all fronts for data manipulation, but suffers simply from the lack of broader R support across the ML and DL space.
The foverlaps function
If this kind of overlapping join is common, shouldn’t someone have developed a package for it? Turns out, data.table has, and with very specific constraints that make it the perfect solution to our problem (if you don’t mind switching over to R, that is).
The foverlaps function has these requirements:
- The input
data.tableobjects have to be keyed for automatic recognition of columns. - The default match type is that it matches all three cases from the image above. Side note: it also has matches for
withinoverlap, matchingstartandendwindows, - The last two matching columns in the join condition in
bymust specify thestartandendpoints of the overlapping window. This isn’t a problem for us now, but does restrict for future uses where we may want non-equi joins on other cases.
The code, si, the code!
Without further ado:
library(data.table)
library(lubridate)
######### BOILERPLATE CODE, NO LOGIC HERE ####################
arrival_time = as_datetime(c(
'2023-01-01 06:23:47.000000', '2023-01-01 06:26:42.000000',
'2023-01-01 06:30:20.000000', '2023-01-01 06:32:06.000000',
'2023-01-01 06:33:09.000000', '2023-01-01 06:34:08.000000',
'2023-01-01 06:36:40.000000', '2023-01-01 06:37:43.000000',
'2023-01-01 06:39:48.000000'))
departure_time = as_datetime(c(
'2023-01-01 06:25:08.000000', '2023-01-01 06:28:02.000000',
'2023-01-01 06:35:01.000000', '2023-01-01 06:33:48.000000',
'2023-01-01 06:36:01.000000', '2023-01-01 06:39:49.000000',
'2023-01-01 06:38:34.000000', '2023-01-01 06:40:48.000000',
'2023-01-01 06:46:10.000000'))
ID = c('A1', 'A1', 'A5', 'A6', 'B3', 'C3', 'A6', 'A5', 'A6')
DT = data.table(
arrival_time = arrival_time,
departure_time = departure_time,
ID = ID)
######### BOILERPLATE CODE, NO LOGIC HERE ####################
# A copy(DT) creates a copy of a data.table that isn't linked
# to the original one, so that changes in it don't reflect in
# the original DT object.
# The `:=` allow assignment by reference (i.e. "in place").
DT_with_windows = copy(DT)[, `:=`(
window_start = arrival_time - minutes(1),
window_end = departure_time + minutes(1))]
# This step is necessary for the second table, but not the first, but we
# key both data.tables to make the foverlap code very succinct.
setkeyv(DT, c("arrival_time", "departure_time"))
setkeyv(DT_with_windows, c("window_start", "window_end"))
# The foverlap function returns a data.table, so we can simply apply
# the usual data.table syntax on it!
# Since we have the same name of some columns in both data.tables,
# the latter table's columns are prefixed with "i." to avoid conflicts.
foverlaps(DT, DT_with_windows)[
, .(docked_trucks = list(unique(i.ID)),
docked_truck_count = uniqueN(i.ID))
, .(arrival_time, departure_time)]
provides us the output:
arrival_time departure_time docked_trucks docked_truck_count
<POSc> <POSc> <list> <int>
1: 2023-01-01 06:23:47 2023-01-01 06:25:08 A1 1
2: 2023-01-01 06:26:42 2023-01-01 06:28:02 A1 1
3: 2023-01-01 06:30:20 2023-01-01 06:35:01 A5,A6,B3,C3 4
4: 2023-01-01 06:32:06 2023-01-01 06:33:48 A5,A6,B3,C3 4
5: 2023-01-01 06:33:09 2023-01-01 06:36:01 A5,A6,B3,C3 4
6: 2023-01-01 06:34:08 2023-01-01 06:39:49 A5,A6,B3,C3 4
7: 2023-01-01 06:36:40 2023-01-01 06:38:34 B3,C3,A6,A5 4
8: 2023-01-01 06:37:43 2023-01-01 06:40:48 C3,A6,A5 3
9: 2023-01-01 06:39:48 2023-01-01 06:46:10 C3,A5,A6 3
Considerations for using data.table
The package offers a wonderful, nearly one-stop solution that doesn’t require you to write the logic out for the query or command yourself, but has a major problem for a lot of users - it requires you to switch your codebase to R, and a lot of your tasks may be on Python or in an SQL pipeline. So, what do you do?
Consider the effort in maintaining an additional dependency for your analytics pipeline (i.e. R), and the effort that you’ll need to invest to run R from Python, or run an R script in your pipeline and pull the output from it back into the pipeline, and make your call.
tags: python - polars - duckdb - R - data.table - foverlaps - overlap - join